I. Introduction into Hive: It’s open source application. It’s built by Facebook. It’s data warehousing application. Hive deals with big set of data. Hive is not good for a small set of data. Hive depends on table base. The format of Hive data could be in text, parquet, Avro and ORC.
II. Hive architecture
1- Meta data: It’s a repository of Hive. This repository contains the information about tables, Table types, partitions of the table, columns of the tables and locations for HDFS as well as Data types.
Embedded Metastore: We use derby database. It runs with same JVM with Hive Client. This type has limitation about the connections between the database and Hive Client. In this type we will have one connection session. This mode is good for unit testing. But it is not good for the practical solutions.
Local Metastore: If we want to use muli-session, we have to use mySQL to open many JDBC connection. But we still have MySQL and Hive Client engine on the same JVM.
Remote Metastore: In this type, we run mySql on remote way. In this case, mySQL will run on the different JVM with different credential account.
2- Parser: It’a parse the queries and divide the queries to different commands with parameters. After that the system will build tree for joins and commands.
3- Optimizer: For optimization solution, Hive uses different engines like MapReduce (Old fasition MapReduce. It’s slow), Tez (Depends on the Graph. It’s framework based on expressing computations as a dataflow graph. It’s faster than MapReduce 100 times) or Spark (It’s memory process with Pipeline. It’s faster than Tez about 100 times).
Optimization techniques
We have some optimization methods can improve the performance of running queries
A. Map join: Map join is very important when we have one table in the join is small. The map join caches the small table to make the join faster.
Example of map join: select /*+ MAPJOIN(b) */ a.key, a.value from a join b on a.key = b.key
B. Bucketing: Bucketing improves the join performance if the bucket key and join keys are common.
C. Vectorized: when we do the operations like scans, aggregations, filters and joins, by performing them in batches of 1024 rows at once instead of single row each time.
set hive.vectorized.execution = ture
set hive.vectorized.execution.enabled = true
4. Logical Analyzer plan:
A. Optimization methods
Combine two star schema
Specify fact and dimension tables
B. Rule base optimization:
Scan the tables
Filters
Join
5. Physical Analyzer plan:
A. Determine the plan for execution
B. Remove unnecessary stages
C. Sort the data to reduce the shuffling
D. Determine the order of execution parts
6. Executor: In this part the system will execute the result for physical and get the result back. In execution engine for Hive, we have three kinds of engine:
MapReduce: It’s the old fashion way to execute the queries through MapReduce model
Tez: Hive system use Apache Tez to run the queries. Tez depends on Directed Acyclic Graphs (DAGs). It uses vertices, and tasks to run run the queries (Graph bases). It’s faster about 100 times than MapReduce
Spark: Hive uses spark. The run will happen in the memory with pipeline capabilities. It’s about 100 time faster than Tez. Also Spark uses DAG concepts.
- set hive.execution.engine = mr;
- set hive.execution.engine = tez;
- set hive.execution.engine = spark;

II. Type of Hive table
A. Managed table: This kind of table is managed by Hive system. In the case of drop the table, we will loose the data also.
CEATE TABLE users_in_canada(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64)
)
COMMENT ‘This is test table’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE;
In this example above, we will create a table (managed table) with row format and comma separate. The data will store as text format.
B. External table: In Hive, we can create external table by specifying the location for the table. In the case of drop the table, we will keep the data in that location.
CEATE external TABLE users_in_canada(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64)
)
COMMENT ‘This is test table’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE
location ‘hdfs://temp/ users_in_canada’;
In the example above, the system will create external table to keep the data in the location hdfs://temp/ users_in_canada
III. Upload data to the Hive
Hive command to upload
> LOAD DATA LOCAL INPATH ‘/home/users.csv’ OVERWRITE INTO TABLE users;
Upload the data to the staging table
– Upload the file to the hdfs path
– Create external table with location to that hdfs path
– Copy the table from staging to final table
INSERT OVERWRITE TABLE staging_users SELECT * FROM final_users ;
IV. Data Types (Column types)
Numeric Types:
TINYINT (1-byte signed integer, from -128 to 127)
SMALLINT (2-byte signed integer, from -32,768 to 32,767)
INT/INTEGER (4-byte signed integer, from -2,147,483,648 to 2,147,483,647)
BIGINT (8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
FLOAT (4-byte single precision floating point number)
DOUBLE (8-byte double precision floating point number)
DOUBLE PRECISION (alias for DOUBLE, only available starting with Hive 2.2.0)
DECIMAL
Introduced in Hive 0.11.0 with a precision of 38 digits
Hive 0.13.0 introduced user-definable precision and scale
NUMERIC (same as DECIMAL, starting with Hive 3.0.0)
String Types
STRING, VARCHAR, CHAR
Misc Types
BOOLEAN
BINARY (Note: Only available starting with Hive 0.8.0)
Complex Types
arrays: ARRAY (negative values and non-constant expressions are allowed as of Hive 0.14.)
maps: MAP (negative values and non-constant expressions are allowed as of Hive 0.14.)
structs: STRUCT
V. Partition the table
The partition is to divide the data set to the different subset of data to avoid the full scan of table during the select statement.
CEATE TABLE users(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64)
)
COMMENT ‘A bucketed sorted user table’
PARTITIONED BY ( province VARCHAR(64))
STORED AS TEXTFILE;
The system will create table users with partition by province

The example allow us to partition the data by province.
A. Partition the table
– Static partition:
The default one in Hive is static partition. The static partition allows us to insert one partition in each statement
Example(1):
insert into users partition (province=’Ontario’) values(‘Bob’,’Brown’,’Address’,’Mississauga’);
Example(2):
We expect the data in the staging table (users_staging)
insert into users partition (province=’Ontario’)
select firstname, lastname, address, city from users_staging;
– Dynamic partition
In dynamic partition, we will insert many partition (according to the data)
Settings in Hive
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
Example(1):
insert into users PARTITION (province)
select firstname,lastname,address,city,province from users_stagin
– Add partition to the table (Alter Table)
Example(1) : with location
alter table users ADD PARTITION (province=’Alberta’) location ‘/path/canada/’;
Example(2) : with location (use default values in the table)
alter table users ADD PARTITION (province=’Alberta’);
– Display partition
show partitions users;
– Add partition by adding file to external table
We use this when we have external table.
- We run hadoop command to build the partition
>hadoop fs -mkdir hdfs://temp/ users_in_canada/province=Saskatchewan - We upload the file with Hadoop command to that folder
>hadoop fs -put users.csv hdfs://temp/ users_in_canada/province=Saskatchewan - Run Hive command:
MSCK REPAIR TABLE users; - Or also we can use another Hive command to add partition
alter table users ADD PARTITION (province=’Saskatchewan’);
-Overwrite in the same partition (If the partition is already there)
Example:
insert overwrite table users partition (province=’Ontario’)
select firstname, lastname, address, city from users_staging;
VI. Skew in join
When we run the query. This query has join for tables. If we have 4 producers. For example the three producers can finish the work for 2 minutes but the fourth producers can finish the work within two hours. At the end the four producers have to wait the fifth producer to continue the work.
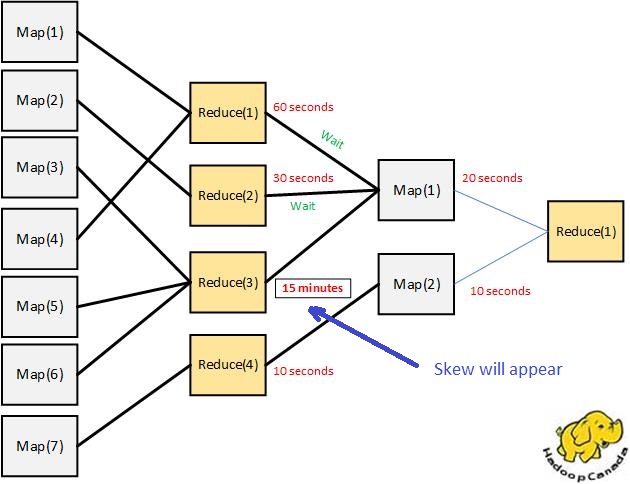
Solution to avoid Skews:
1- Divide the query two two queries
Skew query: select users. firstname, users.lastname, users.address, users.city,provinces.province_population from users inner join provinces on (users.province=provinces.province)
Solution: Divide the query into two queries:
select users. firstname, users.lastname, users.address, users.city,provinces.province_population from users inner join provinces on (users.province=provinces.province) where provinces.province=’Ontario’
Union
select users. firstname, users.lastname, users.address, users.city,provinces.province_population from users inner join provinces on (users.province=provinces.province) where provinces.province<>’Ontario’;
2-Use “Distribute by/clustered by id” in the query
If we have join for the two parts, we can make a sub query and distribute it by id. Please see the example below:
select users. firstname, users.lastname, users.address, users.city,provinces.province_population from
(select users. firstname, users.lastname, users.address, users.city from users distribute by city) users inner join provinces on (users.province=provinces.province);
3- Use “Skew by” when we create the hive table
CEATE TABLE users(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64)
)
COMMENT ‘A bucketed sorted user table’
PARTITIONED BY ( province VARCHAR(64))
SKEWED BY (city) ON (‘Mississaguga’, ‘Toronto’,’Oakville’) STORED AS DIRECTORIES;
The system will create 4 directories as:
hadoop fs -ls /user/hive/warehouse/users
Found 4 items
drwxrwxrwx – mapr mapr 1 2016-05-05 14:56 /user/hive/warehouse/users/HIVE_DEFAULT_LIST_BUCKETING_DIR_NAME
drwxrwxrwx – mapr mapr 1 2016-05-05 14:56 /user/hive/warehouse/users/city=Mississaguga
drwxrwxrwx – mapr mapr 1 2016-05-05 14:56 /user/hive/warehouse/users/city=Toronto
drwxrwxrwx – mapr mapr 1 2016-05-05 14:56 /user/hive/warehouse/users/city=Oakville
The data will have 4 directories and the data will go to the fourth directories depending on the city.
if the city is not in the last, the data will go to the HIVE_DEFAULT_LIST_BUCKETING_DIR_NAME folder
4- Use skew settings
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=500000;
set hive.skewjoin.mapjoin.map.tasks=10000;
set hive.skewjoin.mapjoin.min.split=33554432;
VII. Sort types
A. Order By: It’s same as any order in any database. But the order is happen in one reduce. For example if we have many map or reduce to process the data, after that one reduce will do the order by. In this case the process of query will be very slow.
B. Sort by: The sort will happen at reduce level. For example if we have two reduce the process, the sort will appear in each one and there is no guarantee to order the full set.
C. Cluster by: The cluster by is the result of both order by and sort by.
D. Distribute By: The data set will distribute to the different procedure pending on id. The same id will go to the same producer.
VIII. Clustering the table
We already mentioned about bucket in this article. The fundamental of buckets is very close to partition in Hive Table.
We need to enable bucket in Hive
set.hive.enforce.bucketing=true;
CEATE TABLE users_in_canada(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64)
)
COMMENT ‘A bucketed sorted user table’
PARTITIONED BY (province VARCHAR(64))
CLUSTERED BY (city) SORTED BY (city) INTO 30 BUCKETS
STORED AS SEQUENCEFILE;

The buckets is same as partitions in Hive. In our example above we will try to partition by province and each province has maximum 30 buckets. The city data should go to these buckets and these buckets should be order by city to make the join faster.
IX. Run Hive queries
Writing the query in Hive is same us any database but these queries deals with big set of data. Hive is built for big data set (2 millions records and more)
A. Select Query
Examples:
select firstname, lastname, address, city from users_staging where province=’Ontario’;
select firstname, lastname, address, city from users_staging where province like ‘Ont%’;
B. Join Query
The join in Hive is the same as any database.
Example:
select users. firstname, users.lastname, users.address, users.city,provinces.province_population from users inner join provinces on (users.province=provinces.province)
X . Join types in Hive
Inner join
- Inner join
- Right join
- Left join
- full outer join

C. Semi join
- Left semi join
- Right semi join
