To improve our skills in data science and big data, we have to build our lab on our machine (laptop or desktop). We have to do our practice to improve our skills. We will provide the instructions to build three components (Hadoop, Spark & Jupyter). We will use Jupyter notebook to write the code that works with Spark (data processing) and works with Hadoop to save the data.

I. Applications to install
- Java (OpenJDK 8)
- Hadoop (using version: 3.1.2)
- Spark (using version: 2.7.0 to 3.2.0 preview)
- Anaconda (Jupyter). Windows 7: product year 2018 and Windows 10: product year 2019
II. Java installation
- If you don’t have Java 8, you will need to implement step 1 & 2. If you already have Java 8, you can pass step # 1. Hadoop 3.1.2 works with Java 8.
Install OpenJDK-8 Java. Download and install
https://developers.redhat.com/products/openjdk/download?extIdCarryOver=true&sc_cid=701f2000001OH7JAAW)
2. Add JAVA_HOME to environment variables. (In windows prompt command write variables)

Add JAVA_HOME to path %JAVA_HOME%\bin
JAVA_HOME= C:\AdoptOpenJDK\jdk-8.0.232.09-hotspot
III.Install Hadoop
- Download and install https://www.7-zip.org/ (to unzip Linux)
- Download http://archive.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
- Make directory “bigdata” on c drive “C:\bigdata”
- Unzip hadoop-3.1.2.tar.gz to C:\bigdata\hadoop-3.1.2
- Download Hadoop windows patch https://github.com/cdarlint/winutils

6- Download all patches, unzip the folder and copy Hadoop-3.1.2/bin to bin folder (C:\bigdata\hadoop-3.1.2\bin)
7- Build Hadoop variables:
Go “System properties” Choose “Environment variables”
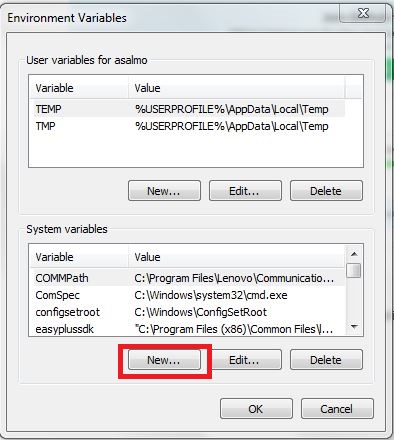
8- Add variables Press “New” to add:
-HADOOP_HOME = C:\bigdata\ hadoop-3.1.2
-HADOOP_BIN = C:\bigdata\ hadoop-3.1.2\bin
-HADOOP_SBIN= C:\bigdata\ hadoop-3.1.2\sbin
-Add % HADOOP_HOME %; % HADOOP_BIN %;% HADOOP_SBIN% to path variable
9- Configure Hadoop to run on single machine
We will need to change the following files (C:\bigdata\hadoop-2.9.1\etc\hadoop):
A.hadoop-env.cmd
B.core-site.xml
C.hdfs-site.xml
D.mapred-site.xml
A- hadoop-env.cmd (Open the file in notepad or notepad++ to edit it):
Change JAVA_HOME variable
From:
set JAVA_HOME=%JAVA_HOME%
To:
set JAVA_HOME=C:\AdoptOpenJDK\jdk-8.0.232.09-hotspot
B- core-site.xml
Open this file to add:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Note: Replace the empty < configuration></ configuration>
C- hdfs-site.xml
Open this file to add:
Note: Replace the empty < configuration></ configuration>
In this case, we will need to make directory for
C:\BigData\ hadoop-3.1.2\data
C:\BigData\ hadoop-3.1.2\data\namenode
C:\BigData\ hadoop-3.1.2\data\datanode
D- mapred-site.xml
Open this file (in notepad or notepad++) to add:
Note: Replace the empty < configuration></ configuration>
10- Formant NameNode:
-Open cmd
Type “hadoop namenode -format”

11- Copy files
One more thing to do: copy hadoop-yarn-server-timelineservice-3.1.2
from C:\bigdata\hadoop-3.1.2\share\hadoop\yarn\timelineservice
to C:\bigdata\hadoop-3.1.2\share\hadoop\yarn
12- Strat hadoop
We need to type start-all.cmd to start all nodes on one machine
You should have:

Now you should have Hadoop on your machine
13- Hadoop Web UI
You can also open http://localhost:8088 and http://localhost:9870 in your browser


Node Manager (http://localhost:8042)

14- Working with HDFS
hdfs dfs -ls /
hdfs dfs -mkdir /test
hdfs dfs -copyFromLocal Sample.txt /test
hdfs dfs -ls /test
hdfs dfs -cat /test/Sample.txt
Reference
- Hadoop reference: https://dev.to/awwsmm/installing-and-running-hadoop-and-spark-on-windows-33kc#comments
- Hadoop Patch reference https://github.com/cdarlint/winutils
IV. Install Spark
1- Download Spark version 2.3 or 2.4 (https://spark.apache.org/downloads.html)

2- Unzip spark-2.4.4-bin-hadoop2.7.tgz
Put the folder in C:\bigdata\spark-2.4.4-bin-hadoop2.7
3- Add to system variables (in the prompt command type “variables”)
SPARK_HOME=C:\bigdata\spark-2.4.4-bin-hadoop2.7
PYSPARK_PYTHON=C:\Users\xxxx\AppData\Local\Programs\Python\Python37\python.exe
PYSPARK_DRIVER_PYTHON= C:\Users\xxxx\AppData\Local\Programs\Python\Python37\python.exe
Add SPARK_HOME to path % SPARK_HOME %\bin
4- Open cmd
Type: “spark-shell” to start spark scala

5- Exit type :q
6- Install Python with Spark
You need to install Python (download: https://www.python.org/downloads/windows/)
Add the variable PYSPARK_DRIVER_PYTHON to computer variables: PYSPARK_DRIVER_PYTHON= C:\Users\XXXXXXXX (Usename)\AppData\Local\Programs\Python\Python37\python.exe
Add the variable PYSPARK_PYTHON to to computer variables: PYSPARK_PYTHON= C:\Users\AppData\Local\Programs\Python\Python37\python.exe
7- Open cmd and type pyspark
8- Start pyspark (Python with Spark)

9- quit from pyspark
> quit()
Reference
V. Install Anaconda (Jupyter Notebook)
1- Download Anaconda (https://docs.anaconda.com/anaconda/packages/oldpkglists/)
Note:
For Windows 7 install Anaconda with 2018 and Python 3.7
For Windows 10 install Anaconda with 2019 and Python 3.7
2- After installation, Go to window search for anaconda After installation (command prompt). Type anaconda

Press Jupyter to start the web notebook.
3- Install findspark for Jupyter (to allow jupyter works with Spark)
Go to “search program and files” write “anaconda”
Choose “Anaconda Prompt”
Write “conda install -c conda-forge findspark”
4- Install Pandas
Go to “search program and files” write “anaconda”
Choose “Anaconda Prompt”
Wite “pip install pandas”